
First steps towards MLOps: Goals, Setup and Initial Operation of an OSS model locally
Back in February I started to take an interest in Artificial Intelligence (AI) given the then recent developments in the field. Since then there has been an explosion of generalized interest in Large Language Models (LLMs), which from where I sit started with the leak of Meta AI's Llama Model. At the time I made a mental note to return later in the year (when I had time) to play around with the technology and investigate applications of Generative AI... Months passed on by with high priority / high stress work commitments dominating my waking hours, culminating in a week long offsite in June.
I resolved to take a 'bi-modal' approach to learning and applying machine learning / AI technology:
- Gain an understanding of the art from first principles to form a foundation for effective use of the technology
- Download, deploy and apply available technology to gain experience in the application of Generative AI
It might come as no surprise to note that this approach lends itself towards unique challenges as I interleave time to both of these avenues of investigation.
This post describes what steps I took to build out a 'functional' ML stack sufficient to download and run freely available LLMs.
As part of my 'download, deploy and apply' workstream I've built out an AI system with an NVIDIA RTX 6000 ADA card paired with a decent CPU/Mobo/RAM combination as a best effort / cost-conscious approach to exploration. While there are online & cloud providers who provide access to GPUs I have to imagine that my use case is at the bottom of any priority list, which is why I invested in a 'minimum baseload capacity' for GPUs. Assembling the hardware was the easy part...
Getting up to speed on deploying a workable software environment for Machine Learning and AI tasks has been a frustrating experience, which I attribute to the break neck speed at which AI developments are occurring. Dependency management and updating toolchains have dominated my time in this early phase exploration. As a result I've entered the world of MLOps.
Installation
This is what I did to get a workable environment to start playing around with LLMs:
Installed Ubuntu 22.04
- Configured ZFS with encryption
- apt install git git-lfs build-essential
- git-lfs is required for pulling data from huggingface
Install the CUDA Toolkit
- Version 12.2 is the most current (I originally ran 12.1, then upgraded...)
- This link will take you to a page to download the Ubuntu dependencies:
- There are instructions that accompany the packages which describe installation
REBOOT
- I can't stress how important it is to reboot after installing the NVIDIA CUDA Toolkit... Things were broken on my system until I did this...
Verify that CUDA is available!
- python -m torch.utils.collect_env | grep CUDA
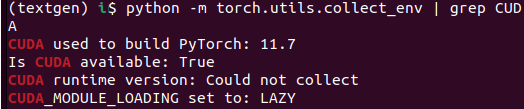
- Ensure that you see 'True' for 'Is CUDA available:'
Download the oobabooga text-generation-webui:
Install conda
- curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
- chmod +x Miniconda.sh && ./Miniconda.sh
- conda create -n textgen python=3.10.9
- Installed to a custom directory
- Said ‘yes’ to the license
- Said ‘yes’ to proceed
- ‘Activated’ the conda
- conda activate textgen
Install python packages:
- conda activate textgen
- pip3 install install torch torchvision torchaudio datasets
text-generation-webui
- Install python requirements
- pip install -r requirements.txt
For GPU acceleration
- pip uninstall -y llama-cpp-python
- CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir
- This will compile llama-cpp-python with GPU support
- CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir
Operating text-generation-webui (aka oobabooga)
Open a shell and type something like this one-liner (be sure to replace your paths!)
$ conda activate textgen && cd /aiml/oobabooga/text-generation-webui/ && python server.py --trust-remote-code --api --listen --extensions superbooga- The --api --listen flags lets the interface be callable from outside the machine (outside of localhost)
- --extensions superbooga loads the extension for using file data as part of queries. There are other extensions you can load as well...
- --trust-remote-code seems to be required for most models as they aren't built in and require executing the model code you download
The terminal will let you know what port you can use to browse to the Web UI
Downloading a Model for use in text-generation-webui (oobabooga)
There is a convenient python script included that you can use to pull models if you have their huggingface identifier (named download-model.py). For example:
$ python download-model.py TheBloke/Llama-2-70B-chat-GPTQ- This pulls down the Quantized version of Llama-2-70B that TheBloke made available to the community
- Other HuggingFace models can be pulled down as well
What about upgrades (MLOps)?
I'm glad you asked... they can be a pain! This is what I had to do when I upgraded from CUDA 12.1 to 12.2 (in support of running the Llama 2 model which came out recently):
- Update CUDA:
- reboot
- git pull from within the text-generation-webui directory
- This ensures that you get the latest updates from upstream
- Update package versions used by text-generation-webui
- cd /path/to/text-generation/webui
- pip freeze > requirements.textgen.complete.txt
- pip install -r requirements.textgen.complete.txt --upgrade
- pip install --upgrade transformers
- pip install --upgrade bitsandbytes
- After updating all of this, I loaded the text-generation-webui
- And I had to wait about 5 minutes for it to spin after starting up before I could load a model
Hopefully all this will be useful to someone (perhaps even myself in a few weeks LOL).