
Black Hat 2018 Session Notes
This year's Black Hat USA conference was pretty solid. Every timeslot had something available that I found interesting and often times I had to pick between competing sessions that captured my interest. Conference organization and crowd control was excellent again as usual. The mobile app this year had more features than in previous years, which I appreciate, though it does lose a few points for complicated and missing capabilities.
For a quick reference on the sessions and tool demos, see the Briefings and Arsenal pages
Check In
Since I checked in on Monday for a training session, the line was short and there was almost no wait. There was an issue with the printer they had to sort out, but besides that things went pretty smooth. Unlike some other conferences, they had me check in with a 'government issue' photo ID. I'm not sure how you would be able to check in if you were, say, 18 and didn't have a driver license for whatever reason.
Navigation
As always, the directions are clearly posted at the stairs, escalators and hallways. They give each attendee a paper booklet with a fold out map that makes it easy to know which level sessions are at. There is a mobile app, and it is better than it's ever been. The only issues I have with the mobile app are:
- It's SUPER slow and keeps trying to refresh over the network each time you visit a session information page
- The map inside the app doesn't tell you which floor you need to be on to reach the session, which is confusing the first day while you try to piece that together
Sessions and Tool Trainings
The quality of presentations was generally high this year. While there were the occasional overly high-level presentation, Black Hat this year largely stuck to providing high quality and detailed content. One thing I really like about Black Hat is the Arsenal which brings developers of open source tools out to Black Hat to show off their work. The standard for admission is pretty high and all the projects I've seen look like stand out tools.
My only suggestion to the organizers: PLEASE move the Arsenal outside of the Business Hall. The noise, distraction and cramped spacing made it a bit of a challenge to line up around the Arsenal booths. Not everyone speaks loudly or has a voice that can easily carry and moving the Arsenal area out would help attendees gain extra value from the event.
I did not the keynote this year, so I can't comment on the content.
Session Notes
Wednesday, Aug 8: Detecting Credential Compromise in AWS
Presented by: Will Bengtson [c/o Netflix]
Tool Release: github.com/willbengtson/trailblazer-aws
Reference Repo: aws-credential-compromise-detection
The focus of this talk is identifying compromised instance credentials being used 'outside' of your AWS environment with an emphasis on session credentials issued and managed by the AWS Security Token Service (STS). In an environment as large and complex as Netflix it can be challenging to detect if an attacker is using your credentials from some other AWS account.
One thing he emphasized is that it's likely the attacker will be operating from inside AWS, just like you and quite probably your competitors. This gives them easy opportunity to leverage AWS services against their targets.
To keep track of when and where session credentials are issued/used you must harness CloudTrail, which keeps a log of all Amazon AWS Service events that transpire within your AWS Account(s). Recently AWS expanded the amount of cloud trail logs you can query from within the Web GUI to 90 days. This expanded timeframe of searchable events makes it easy to answer quick, ad-hoc questions about your environment.
While being able to do a query in the GUI is handy, the presenter has a goal of automation. And at Netflix they have multiple AWS Accounts (he didn't say how many, but we are left to assume quite a few). The best practice is to consolidate the storage of AWS Cloud Trail logs to a single S3 bucket which can then be queried.
Once CloudTrail is configured, you can have a tool scape the logs for all known accounts (be advised there is up to a 20 minute time lag for events to make it into the bucket!)
The tool he came up with looks specifically at a couple of fields within cloud trail event log entries (** I may have the casing wrong here...):
- eventType
- SourceIP
- UserAgent
Through developing this tool he learned that querying all cloudtrail events can take forever. It may take all day just to get any results back, which is pretty far from real time. To speed up the system, he had to make an assumption:
- The first use of a temporary credential (via AWS AssumeRole) is considered to be the proper owner of the credentials
With this assumption, his tool can pair the IP address of the EC2 instance with the credential. If any other instances try to use that credential, their IP address won't match and will get flagged. One suspicous AWS call to watch out for is GetCallerIdentity (which is like 'whoami' but for AWS. An attacker would want to know what they are working with)
Edge cases to account for:
- AWS Makes a call on your behalf, in which case the IP address is replaced with
.amazonaws.com - You have an AWS VPC endpoint for AWS Services, in which case you will see an address something like 192.168.0.2 (My notes are unclear how this value was arrived at)
- A new ENI (Enhanced Network Interface) is attached or associated with a new address, in which case there could be a new address
By getting Session credentials, an attacker could force an SSRF (Server Side Request Forgery) to make a call. Or do something else.
The work described here has a prototype implementation available from Netflix on Github: aws-credential-compromise-detection.
Wednesday, Aug 8: Deep Neural Networks for Hackers: Methods Applications and Open Source Tools
Presented by: Joshua Saxe [c/o Sophos]
Author of: Malware Data Science: Attack Detection and Attribution
I appreciated the broad coverage of this presentation and left with a greater understanding of how Deep Learning can be leveraged in InfoSec. He classifies Security Data Science into 3 categories:
- Visualization
- Machine Learning
- Deep Learning
In fact, he encouraged everyone in the presentation to become a Security Data Scientist as data science is about learning and inferring from data and infosec is about identifying patterns and trends to interpret malicious data or actions
The emphasis of this talk is on Deep Learning. Apparently it is relatively new (maybe 10 years old?). In that time it has come a long way. Some examples listed during the presentation:
- Real-time computer vision identifying objects and people in a 30fps movie
- Neural net learning to play super mario (without guidance from humans)
- New content generation (images, video) [Useful for creating convincing sock puppet social media accounts]
- Generate source code
Sophos created a neural net to calculate a threat score on previously unseen urls by feeding in a training sample of 125 million URLS (50% known good, 50% known bad). See the arxiv entry on eXpose for more details. In their testing they found a combination of deep learning + signature analysis nets them about a 95% discovery rate on previously unseen Zero Days (as opposed to just 85% effective with only signatures).
Neural networks / Deep learning has its limits. When properly used it can be quite effective, but if you take it too far you get weirdness. He showed several AI generated memes that were awful too, but no links for those!
How does Machine Learning work? The idea is to plot attributes of what you are looking at in space, then come up with a geometry/math solution that can be used to cleanly delineate between data points. In this case, the example was a stripped-down set of attributes from executable file samples plotted in 3D space to easily show how this works.
Terms:
- Feature - this is a specific 'attribute' of the data you are modeling. In the executable file example above, 'file size' is an attribute and plotted on an axis
- Machine Learning Math Boundary - This is the tricky geometry math that is used to find a boundary between the known good and known bad samples (in the example above: non malicious vs malicious binaries). Deep Learning uses a NONLINEAR decision boundary
- ML Networks - The 'math machines' that find the decision boundary
- Decision Boundary - specific math that describes where data lies on the spectrum. is it 'good' or 'bad'?
- Neural Network - simulates crude brain neurons but in software. neurons can be linked to each other, with each 'link' having a 'weight'. You can feed the output back as input to get automatic weight tuning (in some cases, not all the time)
In real life, you have WAY more than just 3 dimensions- likely hundreds or thousands. This is hard for a human to visualize, even though it is still 'just geometry'.
Also interesting: Neural Networks are very performant in higher dimension space (like having a 100 attributes per executable binary)
How do Neurons compute?
- Each neuron is a computational unit (you can have different types)
- Neurons output a SINGLE value, no matter how many input links it has
- For each input, it takes the VALUE of the input and MULTIPLIES it by the weight of the link. (ex: Input value is 4, weight is 0.25). All inputs are added after being multiplied by their weights
- If the COMBINED value of all inputs is greater than zero, the output will be the value... but if the output is BELOW zero, then nothing is output (just 0)
How do weights get auto-tuned through the training process?
- Each network has a certain number of weights
- Each weight is a DIMENSION (feature or attribute of your dataset)
- The value of each data point is plotted
- The neural network can see if it is getting closer or further away from a solution, and it moves across the entire dataset calculating the optimal path. This works on a point-by-point basis as the neural network can't "see" the entire picture all at once
- There are different algorithms for this optimal path calculation (momentum, gradient descent, and others)
Convolutional Neural Networks:
- A different 'type' of neuron that can be used in Deep Learning
- These neurons can LEARN which attributes or features to scan for
- They can be layered for effectiveness. For example: Find shape primitives -> Look for faces -> look for 'facial architypes' -> check for an individual's face
Convolutional neural networks can feed into 'traditional' neural networks for decision making.
You don't have to just use graphical data with convolutional neural networks. In the example of the URL Threat Score, they set it to analyzing character strings with a resolution of 2, 3, 4 and 5 characters. The threat score model used 1024 convolutional neurons.
With Introspection you can examine the neural network weights to try and see how the network is 'thinking' about problems. In the example of the URL threat score they found that the network:
- Classified Upper case letters as similar
- Classified Lower case letters as similar
- Classified Special characters as similar (all this without human guidance, these were features that were DISCOVERED)
He thinks of this like a 'Neural Regular Expression', but better as you get the degree of the match in addition to 'did it match'
Tools
- pytorch - Another high level library that sits on top of tensor
- keras - A popular high level library that uses Tensor Flow
- tensorflow - Low level library for ML/Deep Learning
- sklearn - some ML tools
- python
- linux
- matplotlib
- numpy
- scipy2017
- learn
- seaborn - statistical data visualization
This was easily one of the best presentations I attended at Black Hat. Well thought out and well presented.
Wednesday, Aug 8: Compression Oracle Attacks on VPN Networks
Presenter: Ahamed Nafeez
Tool Released: VORACLE (** The github doesn't seem to work: https://github.com/skepticfx/voracle)
Even though the TLS CRIME and BREACH attacks are well known, little was spoken about how this class of attacks could impact VPN networks. Compression Oracle attacks are not limited solely to 'TLS protected data'. VPNs offer a feature usually known as TCP compression which behaves similarly to TLS compression.
The presenter focused on OpenVPN since that is commonly used by VPN as a Service operators since it is open source and well understood. OpenVPN allows for lz0, lz4 and lz77 family of compression.
If you rely on a VPN connection to protect HTTP traffic streams, you do not have the full degree of security you might assume if compression is enabled. The best mitigation is to force HTTPS over VPN. The attacker needs several things before they will be able to read leaked secrets over VPN:
- Your VPN connection needs to use compression
- The attacker can observe the VPN traffic
- The attacker can get the victim to visit a webpage
He demonstrated how he can steal a sessionId cookie from a cross-domain website (sample site: http://insecure.skepticfx.com/)
Challenges in his research:
- VPN is pretty 'chatty' since everything is tunneled over the connection (It can be hard to identify traffic)
- Chrome browser is immune to the issue he discovered since it splits the http headers request and body into different requests (Firefox doesn't do this, and was used for his demo)
How can this be fixed?
- Disable compression (OpenVPN enhanced their documentation to illustrate the risks of running with compression)
- Look at the approach SPDY took- it was susceptible to CRIME. Their 'fix' is to selectively disable header compression for sensitive fields (HPACK). There are literals that are never indexed from the http2-spec. (From my vantage point as an attendee, this approach seems a bit hacky...)
- Don't rely on VPN to protect vanilla HTTP sessions
Wednesday, Aug 8: An Attacker Looks at Docker: Approaching Multi-Container Applications
Presenter: Wesley Mcgrew
The presenter examined Docker from a red team point of view. As a red teamer, he and his teams need to quickly get up to speed on new technologies (ideally before visiting a customer for an engagement!). An emphasis he returned to during the presentation is that a redteam pentester's skillset is creeping towards an AppSec specialty. I would say maybe towards more of a 'DevOps' specialty.
Developers and development organizations within companies are constantly pushing out towards leading edge technologies. Devs want to work fast, companies want to release product and meet their market window. Because of this, new technology finds its way into pen test customers environments and pentesters need to keep up.
Since Docker is just another abstraction, it doesn't change much about specific technologies running within Docker. You can retain your Apache, MySQL and other technology experience and it will still serve you well. Since it is a new technology, it does require reading more documentation and getting up to speed.
Where he likes to start is looking at the 'hello, world' and getting started tutorials that actual devs will use when learning a new technology. This helps you understand how they are leveraging the technology so when you find gaps you can have an idea of how to exploit their assumptions. The presenters inspiration for this technique comes from DEF CON 15: Tactical Exploitation talk given by HD Moore.
Key point: the WAY developers use docker opens them to more issues than just exploits in the tool itself. Developers may not understand the nuances of the technology. Consider:
- Containers share the same kernel with the physical or virtualized host they run on (like a chroot jail, kind of)
- Container Images store configurations for applications, often times in publicly accessible registries (giving you a one-stop shop to view a machine state and poke for vulnerabilities). Images may contain secrets as well
- Developers choose default settings unless they are forced to choose otherwise. Any gap in the permissions the tool uses and those it needs increases attack surface area
Vulnerability Lifecycle: A vulnerability does not begin when it is DISCOVERED, it originates in a MISTAKE. The flaw could be at the code level, design/architecture decisions or the business problem itself. There may be more than one flaw leading to a vulnerability.
Everything in computer science is an abstraction running on top of silicon. If you can exploit assumptions BETWEEN layers of abstraction you may be able to find a vulnerability. Examples given during this talk include the broad categories of 'web app vulnerabilities' and 'memory corruption'.
Attackers have to work at lower layers of abstraction than either defenders or developers. They HAVE to learn all possible technologies a target might use to have a chance at exploiting the attack surface area exposed by the developer.
Another consideration: with new layers of abstraction it becomes easier for developers to do work. This lowers the bar for development talent and as more people do this work with less understanding of the abstractions involved it becomes easier or more likely that an assumption can be exploited.
As far as containers are concerned, one downside is that you may need to import your own tools. Many developers use stripped-down container images that don't include common tools (maybe not even vim!). Because of this you may need to be a bit more noisey and transfer over your tools of choice.
Another downside is that if you find a potential issue (buffer overflow, for example) and it kills the container process, the container is likely to be killed by the orchestrator and replaced with a fresh instance. You may lock yourself out of the environment if you are not careful
Thursday, Aug 9: The Problems and Promise of WebAssembly
Presenter: Natalie Silvanovich (Google Project Zero)
Natlie covered the basics of what Web Assembly (WASM) is:
- W3C standard
- Compiled binary executables that run inside your browser
- Tighter/more efficient than JavaScript due to limited instruction set
- Untyped 'linear memory' storage model
- Does not interact with the DOM (so, no avoiding javascript... in the browser)
- Single threaded (retains the JavaScript thread model)
Web Assembly concepts:
- Web assembly 'modules' can communicate with each other and with JavaScript
- Memory is 'linear' in nature, meaning that there is ability to allocate memory at arbitrary addresses. All memory used in a WASM module is expressed as byte offsets from a starting memory segment.
- Memory can be grown but never shrunk
- Minimal instructions that can access memory (basically just load and store)
- JavaScript can view WASM module memory at any time
- Safe Signal buffers (on 64 bit platforms) which means that memory operations are incredibly fast and you only get a hit when there is some sort of memory related issue (you get a javascript exception generated at that point)
In Web Assembly there is a distinction between 'code' and 'data'. Functions are separated into their own Function Table to prevent instruction/data interleaving.
She covered a number of real-world CVEs that have been discovered in various WASM implementations. The current conclusion is that WASM is reasonably hardened from a specification standpoint, though that may change if these proposed features make it into the WASM specification:
- Concurrency
- Native garbage collection
Thursday, Aug 9: The Windows Notification Facility: Peeling the Onion of the Most Undocumented Kernel Attack Surface Yet
Presenters: Alex Ionescu & Gabrielle Viala
Tool Release: They will release and open source their toolset after working with MS on bugs
Tool: mach2 (not by the presenters, but called out)
This session covered the Windows Notification Facility in depth. Specific APIs were called out and a good developer level overview of the technology was given. WNF is a Kernel level feature that is 'undocumented' (introduced in Windows 8). It is a pub/sub implementation with a couple of interesting features:
- Subcribers can listen for a subscription BEFORE it has been created
- It can handle both persistent and volitile data
- Easy for subscribers to check IF/WHEN updated data is available from their subscription, or if an update has already been written to the subscription so you can avoid double-posting (or posting outdated) events
Why does this exist in the kernel? He gave an example for where it could be useful: Let's say you are a windows kernel driver and want to know when the disk is available to write to (on start the boot disk is mounted read only). WNF makes it easy for drivers to subscribe to a channel (that doesn't exist yet, possibly, based on boot order initialization in the kernel) and wait for the 'RW' signal to be sent. Without WNF abstraction it can get a little complicated to bootstrap this process.
WNF identifies pub/sub subscriptions with "State Names":
- May look like 'numbers' in a debugger- don't be fooled, there is an encoded data structure there
- To examine the encoded data structure you need to XOR with a specific hex magic number (listed in the slide deck, once published)
- State Names can be classified as Well Known (provided by Windows), Permanent and Persistent. (Mention is made of Volatile as well, which don't persist past process termination)
You can get EXTREMELY granular with WNF 'state scopes'. These allow you to define which group of processes (or users, or machines, etc...) have access to the WNF state name and what level of access is granted.
Each state name has a 51bit unique sequence number to ensure uniqueness, with different formats for each type of state name. These names can be brute forced (using a tool that the presenters will eventually open source)
WNF Attack Surface:
- Zero-byte Write attack: You can overwrite a WNF state with '0 bytes', which disrupts what the publishers and subscribers expect from their WNF state subscription. If you update the change time stamp, it prevents publishers from overwriting your zero bytes with correct information and effectively stops communication. (They found that if you do this, you can kill your windows instance and it won't come back up after a reboot, and that standard, normal privileged users can do zero byte writes)
- Crashing Service attack: You have to be an admin for this to work, but he could get services to crash with null pointer issues
- Covert Side Channel: you can pass data over WNF states and pretty much any EDR tool is going to miss it. If you use a volatile channel there won't even be anything written to disk. Using a 'well-known' name would be hard to detect as well as those are expected to be in use, so even if a vendor is looking this could be hard to see.
- Information Disclosure: WNF is used by a lot of windows subsystems and applications. There is a lot of potentially interesting information shared over this channel that you can access if you only subscribe. For example, you can subscribe to USER_PRESENT/USER_PRESENCE_CHANGED to see if anyone is at the computer. Or, if you want to know every web page visited by MS Edge, subscribe to WNF_EDGE_LAST_NAVIGATED_HOST. (these channels keep getting updated, so you'll get more than just the 'last' visited page if you keep listening!
The presenters note that memory pointers or executable code could be easily passed by WNF states, so app developers may use this feature as an easy way to do this between executable processes in their applications. As attackers you could then pass arbitrary executable code and (since WNF states include a callback) have an entry point to potentially execute that code.
Thursday, Aug 9: AI & ML in Cyber Security - Why Algorithms are Dangerous
Presenter: Raffael Marty
This presentation sounded interesting to me since it seems like nearly every vendor is touting their 'Deep Learning' and 'AI' expertise. I wanted to see an alternate point of view. While I don't agree with everything presented, it was interesting to see a contrarian view to Deep Learning.
The session opens with a slide summarizing his views on 'AI':
- Algorithms exist, but no AI yet
- These algorithms get smarter, but they are not a substitute for Domain Expertise
- It's frustrating to see people 'throwing algorithms against the wall' to see what sticks. Where is the understanding of the problem space?
- Invest in people, not learning systems
- Build systems that capture expert opinion
- Don't focus on history as a predictor of future events - think outside the box
He then moves on to describe that Machine Learning is an algorithmic way to describe data. It comes in 2 modes (supervised/unsupervised). Deep Learning builds on ML to eliminate a time intensive step: Feature engineering [features are basically attributes in your dataset that are significant to your analysis]. Deep Learning (in his opinion) has an issue with explainability and verification: how did your neural net get to the answer? What is it 'thinking'?. He asserts that this makes it not much more useful than regular old ML.
Where is "AI" used in InfoSec today?:
Supervised Uses:
- Malware classification
- Spam identification
- MLSec (A project by Alex Pinto) for analyzing firewall data
Unsupervised Uses:
- DNS analytics
- Threat intelligence
- Tier 1 security analyst automation
- User and behavior analytics (mostly just statistics)
The presenter goes on to list failures of specific deep learning systems that have been publicized over the years:
- HP's racist camera software
- Gender biased ads (from a Carnegie Mellon study)
- Googles "gorilla" identification issue with images
- Microsoft's AI chatbot "Tay"
- Propublica article on racial bias in predicting future criminals
- ML being used to judge a beauty pageant and geting racially biased results
I agree that these are all failures and that they are disturbing in their similarity. It feels a bit alarmist to extend this to examining information security related events, though, as the modelling in infosec is different.
The presenter describes what makes algorithms dangerous in his eyes:
- They make assumptions about the data
- Software to analyze data with algorithms is too easily available, meaning more people will use it
- Algorithms don't take domain expertise into account. He lists an example where ML found 'TCP port 70,000', which clearly doesn't exist
- You need a good training data set, which can be hard to find.
I found point number 2 to be kind of interesting. My opinion is that a lower barrier of entry gets more people into the field, which lets more people identify specific limits and 'gotchas' in the technology. It seems likely that with more eyes and practice the field will get better, faster over time (though this is not what the presenter is trying to drive at).
He goes on to present his views on the dangers of Deep Learning:
- Not enough quality labelled data
- Issues with data cleanliness
- Data normalization issues (like timezones)
- Lack of domain experts to classify data
- Can you explain what your Deep Learning model actually 'learned'? Is the output verifiable? How can you interpret the output?
The presenter proposes an alternate approach to ML/Deep Learning (which, paradoxically, some 'experts' have discounted as being too complex to work. Given his emphasis on appealing to Expert Authority in the session, I found this kind of ironic!): Probabilistic Inference[Bayesian Belief Networks]
I've included a picture of the slide that describes this here:

A key theme in the presentation is that Experts are required to make a good system. He mentioned to the room that nobody's job is at risk from ML/Deep Learning. In my experience relying on the fallacy of 'Appeal to Authority' can cause overt or subtle issues that can be difficult to weed out. If you do involve 'expert' input, take it for what it is as opposed to who said it.
I wonder if we aren't setting an arbitrary bar for Deep Learning. While there is a ton of marketing hype out there that isn't true, can't it be an effective tool for what it does do? It feels like a fools choice to say or imply that Deep Learning needs to be 'AI' or we should toss it in the garbage heap.
Thursday, Aug 9: WebAssembly: A New World of Native Exploits on the Browser
Presenters: Tyler Lukasiewicz & Justin Engler
References:
- https://www.pnfsoftware.com/reversing-wasm.pdf
- https://www.fastly.com/blog/hijacking-control-flow-webassembly-program
- https://github.com/kripken/emscripten
These guys focused on the AppSec side of Web Assembly, with an emphasis on compiling C code to run on Web Assembler. They list a few interesting uses of Web Assembly:
- Archive.org emulators
- Cryptocurrency miners
- Porting desktop applications to web browsers
And more interesting uses that are upcoming for the technology:
- browsix - POSIX in WASM
- jslinux - Emulates an OS inside a browser
- runtime.js - Microkernel in WASM (Node.js)
- nebulet - Microkernel without ndoejs
- cervus - Run WASM that lets you hook your kernel (!!)
- cranelift - Takw a WASM module and turn it into a thick client binary (ELF, PE, etc...)
- eWASM - Ethereum language runtime
They note the feature (if not implementation) level similarities with Java Applets:
- Sandboxed
- Virtual Machine based, with it's own instruction set
- Runs in your browser
- Write once, run anywhere
- In the future, it will be embedded in other targets besides web browsers
(They wonder if the creators of Web Assembly appreciate the irony of what they want to accomplish)
What is WASM?
- Should probably have been called "Web Byte Code" instead of 'Web Assembler"
- Stack based machine (No 'registers')
- Every operation either pushes or pops values from a stack
- Incorporates "linear" memory, no direct access to system memory. Everything in this linear memory space is untyped
Phone shot the 'Wasm stack machine':
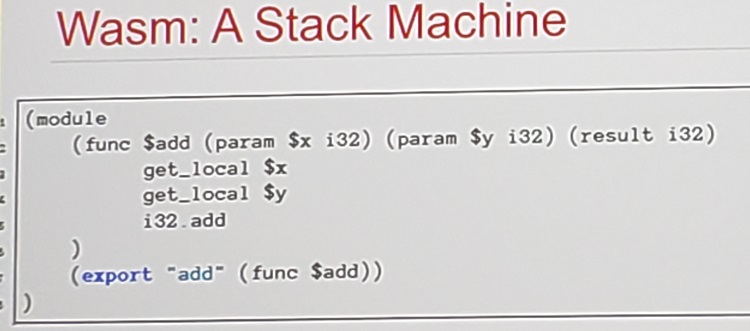
WASM incorporates the idea of separating instructions from data. Function Tables let you jump to specific functions that you have defined that do work.
WASM in the browser:
- No access to system memory
- No access to the DOM
- Functions can be exported to JavaScript
- JavaScript can read WAM Module memory as an ArrayBuffer
- Memory can be shared across instances of WASM
How do you use WASM today? use the emscripten project which can compile C/C++ to Web Assembly.
Will old exploits work in Web Assembler? Exploits that should work:
- Integer Overflows (fewer types in WASM, so keep that in mind)
- Buffer overflows (in specific contexts, harder to get arbitrary code execution in WASM)
- C format string attack
- Time of Check / Time of Use
- Timing side channel
- Heap
Exploits that probably won't work:
- "Classic" buffer overflow
- ROP
- Information leakage from browser (implementation dependent)
A note on number passing:
- WASM: int32, int64, float32, float64
- Javascript: 2^53 -1 (on 32bit: 2^32 -1)
- C: Many, many data types
New exploits:
- Buffer Overflow -> XSS (if you overflow what is written to the DOM, you can inject unexpected values)
- File Processing Overflow (requires emscripted_run_script to be in your function table)
- Server side RCE (if the server is running Javascript)
Thursday, Aug 9: Automated Discovery of Deserialization Gadget Chains
Presenter: Ian Haken Tool: https://github.com/JackOfMostTrades/gadgetinspector
Summary: how do you know if your specific set of java classes on your classpath can make you vulnerable to deserialization vulnerabilities? Ian wrote a tool you can use to find out- it operates on bytecode so it doesn't just have to be "java" (scala, groovy, flavor-of-the-week, etc...). It has some assumptions, but has been used to good effect within his company. A nice feature is that it can scan proprietary classes that you don't have source code for. Now the tool is open sourced.
Tools referenced in the talk:
- ysoserial
- marshalsec
- joogle
- java deserialization scanner
- NCC group burp plugin
(these are all fine tools, but they don't tell you about YOUR java classpath)
Other solid presentations I visited, but didn't have good note taking handy:
Wednesday, Aug 8: AFL's Blindspot and How to Resist AFL Fuzzing for Arbitrary ELF Binaries
Presenter: Kang Li
Blurb from the Black Hat page:
AFL has claimed many successes on fuzzing a wide range of applications. In the past few years, researchers have continuously generated new improvements to enhance AFL's ability to find bugs. However, less attentions were given on how to hide bugs from AFL.
This talk is about AFL's blindspot — a limitation about AFL and how to use this limitation to resist AFL from finding specific bugs. AFL tracks code coverage through instrumentations and it uses coverage information to guide input mutations. Instead of fully recording the complete execution paths, AFL uses a compact hash bitmap to store code coverage. This compact bitmap brings high execution speed but also a constraint: new path can be masked by previous paths in the compact bitmap due to hash conflicts. The inaccuracy and incompleteness in coverage information sometimes prevents an AFL fuzzer from discovering potential paths that lead to new crashes.
This presentation demonstrates such limitations with examples showing how the blindspot limits AFL's ability to find bugs, and how it prevents AFL from taking seeds generated from complementary approaches such as symbolic execution.
To further illustrate this limitation, we build a software prototype called DeafL, which transforms and rewrites EFL binaries for the purpose of resisting AFL fuzzing. Without changing the functionality of a given ELF binary, the DeafL tool rewrites the input binary to a new EFL executable, so that an easy to find bug by AFL in the original binary becomes difficult to find in the rewritten binary.
Wednesday, Aug 8: Breaking Parser Logic: Take Your Path Normalization off and Pop 0days Out!
Presenter: Orange Tsai
Blurb from the Black hat page:
We propose a new exploit technique that brings a whole-new attack surface to defeat path normalization, which is complicated in implementation due to many implicit properties and edge cases. This complication, being under-estimated or ignored by developers for a long time, has made our proposed attack vector possible, lethal, and general. Therefore, many 0days have been discovered via this approach in popular web frameworks written in trending programming languages, including Python, Ruby, Java, and JavaScript.
Being a very fundamental problem that exists in path normalization logic, sophisticated web frameworks can also suffer. For example, we've found various 0days on Java Spring Framework, Ruby on Rails, Next.js, and Python aiohttp, just to name a few. This general technique can also adapt to multi-layered web architecture, such as using Nginx or Apache as a proxy for Tomcat. In that case, reverse proxy protections can be bypassed. To make things worse, we're able to chain path normalization bugs to bypass authentication and achieve RCE in real world Bug Bounty Programs. Several scenarios will be demonstrated to illustrate how path normalization can be exploited to achieve sensitive information disclosure, SMB-Relay and RCE.
Understanding the basics of this technique, the audience won't be surprised to know that more than 10 vulnerabilities have been found in sophisticated frameworks and multi-layered web architectures aforementioned via this technique.